FAIR Data Principles
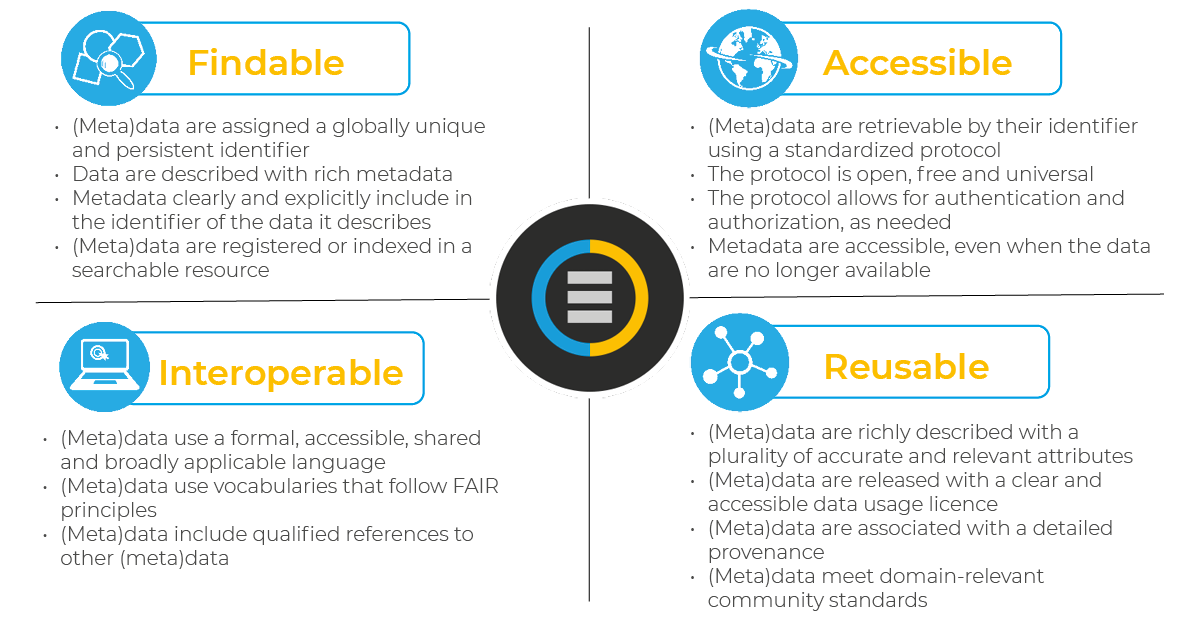
Findable, Accessible, Interoperable, and Reusable (FAIR)
The FAIR Data Principles set out criteria that enable the philosophy of openness to be realized in a tangible way through modern publishing practices and infrastructures that support current data science needs.
The FAIR Data Principles were formulated after a workshop held in Leiden, Netherlands in 2014. They were nurtured by FORCE11 before formal publication in Nature Scientific Data in 2016.
How is CCDC FAIR?
The FAIR Data Principles help guide all of our data decisions. Ways in which the CCDC enacts the FAIR Data Principles include:
- Ensuring machines can reliably understand crystallographic experiments, data, and knowledge by using standard formats and vocabularies.
- Adopting persistent identifiers to identify datasets and their contributors.
- Leveraging standard identifiers such as InChI to link datasets to a range of chemistry resources.
- Ensuring metadata is harvestable by machines to enable interoperability with other information resources.
- Providing searchable resources that enable the discovery of data through interfaces designed for both humans and their machines.
How does the Cambridge Structural Database enable FAIR?
The structure and design of the Cambridge Structural Database (CSD) is central to our FAIR activities. In particular:
- It enables the discovery and reuse of historical crystallographic information by humans and machines.
- It allows knowledge to be derived from this information and applied across domains.
- It is accessible to humans through various web and desktop tools.
- It is accessible to machines through the CSD Python API.
Why Adopt FAIR Data Principles?
Analyzing the growing amounts of data in the life and physical sciences already presents a daunting task, and the amount of data grows larger and more diverse every day. In addition, artificial intelligence and machine learning initiatives require high-quality, machine-readable data that is also semantically linked. Adhering to the FAIR Data Principles helps ensure your data:
- Supports next-generation research around the globe.
- Works well with machine learning (ML) and artificial intelligence (AI) models.
- Remains orderly and accessible at all levels of your organization.
- Can support iterative learning on past work, saving time and resources.
FAIR for Humans and Machines
The FAIR Data Principles emphasize the need for findability, accessibility, interoperability, and reusability of data for both humans and machines. Today’s ML and AI technologies require data that can be meaningfully and accurately interpreted by machines. A dataset that satisfies the criteria set out in the FAIR Data Principles is more likely to meet such requirements and be fully AI-ready.
Knowledge Graphs: The CCDC’s BioChem Graph Project
We at the CCDC remain committed to ever improving our data in accordance with the FAIR Data Principles. In July 2020, we started a collaboration with the Protein Data Bank in Europe (PDBe) and ChEMBL—both based at the European Bioinformatics Institute (EBI)—on the BioChemGRAPH project. Knowledge graphs are growing in prominence as key enablers of data analysis, but their design and population require careful planning and well-ordered data.

The BioChemGRAPH project will create a knowledge base that links together 3D structural data relating to biological macromolecules in the PDB, bioactivity data of molecules with drug-like properties in ChEMBL, and structural chemistry data of small molecules from the CSD. This will allow researchers to:
- Quickly access relevant information from trusted but disparate datasets.
- Leverage a variety of experimentally determined and calculated properties on small molecules.
- Advance work in fields like target validation, drug development, drug repurposing, and cross-reactivity.
By expanding our dedication to the FAIR Principles to the broader community, we’re helping to ensure that researchers worldwide have comprehensive and immediate access to the world’s best structural data and knowledge.