The journey to one million crystal structures continues…
Later this year the world of structural chemistry will reach a tremendous milestone, the sharing of one million organic and metal-organic structures through the Cambridge Structural Database (CSD). The CSD was one of the first numerical scientific databases to be established and today enables scientists and educators in over 70 countries to learn from the data.
The journey towards the sharing of one million structures can be traced back to the 1950s and J.D.Bernal. Bernal believed that the collective use of data would lead to the discovery of new knowledge; transcending the results of individual experiments.1 Olga Kennard decided with Bernal’s support to examine the influence of molecular shape on crystal packing. In 1965 a grant was awarded to allow a small team to start work on what is now known as the Cambridge Structural Database. There were already nearly 4,000 published structures, so collating these was a daunting task but given the growth of published structures in the following years it was fortunate that efforts started when they did.
Initially, data was released in the form of a book – it took five years to collate the first volumes in the Molecular Structures and Dimensions series in 1970. More volumes followed until the early 1980s, when they gave way to a more modern computational database. If the CSD was still released in book form today then it would consist of over 450 volumes! The volumes were electronically typeset, a huge achievement at that time, and consisted of bibliographic information as well as introducing rudimentary ways of searching through permuted name indexes and dividing the entries into classes. By volume 13 computer-produced diagrams of the chemical structure were added to illustrate each compound, greatly extending the utility and usability of the series. It was decided at the outset that the accuracy of the database was paramount. This meant users had numbers they could rely on and could use the database with confidence, which is certainly still true today. To enable this, an elaborate set of checks were introduced, and authors were contacted if issues with a structure were found. Two volumes of interatomic distances were also created and a database system was constructed. By 1979 the database contained nearly 25,000 structures, having doubled in size in five years preceding this. It was recognised that it would be a huge challenge for researchers to analyse and utilize such a large volume of information and so a computer-based search, retrieval, analysis and display system was designed.2

Early versions of the CSD in book form alongside a later version of the CSD on CD
In the 1980s this system, known as the CSD-System, was distributed in more than 30 countries worldwide, and interest in the CSD-System from pharmaceutical and agrochemical companies increased significantly. Income from these companies, coupled with support from National Affiliated Centres, enabled the CCDC to become an independent, non-profit charitable centre in 1987.
Today functionality in the CSD-System includes powerful 2D/3D searching, extensive geometry analysis tools, intermolecular interaction analysis, high impact graphics generation, and interconnectivity via the CSD Python API. The ability for users to gain new insights is aided by the addition of two knowledge bases known as Isostar and Mogul which provide information about intermolecular interactions and molecular geometries respectively.
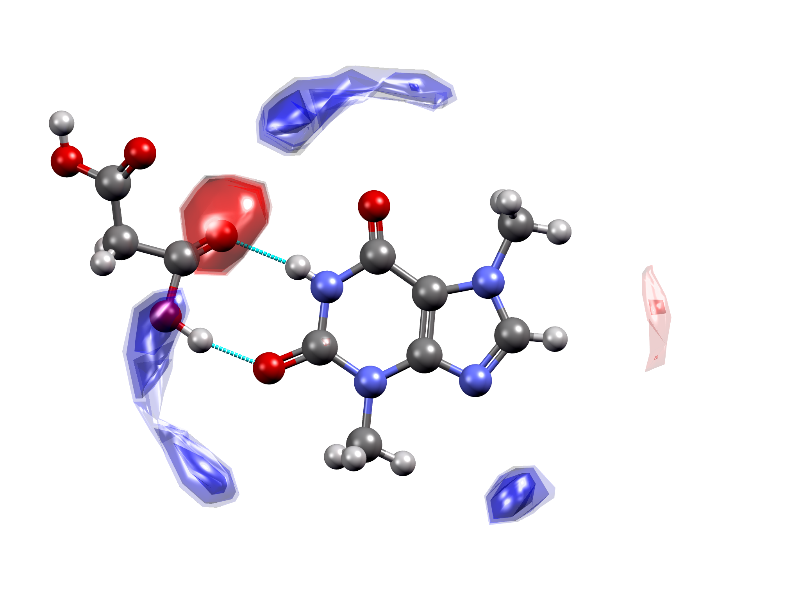
A Full Interaction Map showing a molecule’s interaction preferences, one of the many ways the data in the CSD can be used today to generate new insights
CCDC software products have diversified to make maximum use of structural data and are used worldwide in industries ranging from pharmaceuticals and agrochemicals to catalysis and gas storage. The CSD is also used extensively in teaching thanks to the fact that each individual dataset is free to view and retrieve, with a range of educational resources made available alongside the data.
The widespread use of structural data worldwide, the reliance on the CSD and associated software in drug discovery and development, and the thousands of research papers published using the CSD are testament to the fact that the collation and curation of individual experiments has enabled new insights and knowledge from the data, making it so much more than the sum of its parts.
Our attention now turns to one million structures, which we expect to be reached this summer. You can view our millionth structure “countdown” on our website homepage and also sign up to hear the latest news from the CCDC and learn more about how we will be marking this milestone.
We will be celebrating at regional crystallographic conferences including the European Crystallographic Meeting (ECM) in Vienna and the American Crystallographic Association (ACA) meeting in Cincinnati. The value of crystallographic data will also be demonstrated at chemical conferences such as the Fall American Chemical Society Meeting, and the Cambridge Science Festival. So keep up to date on our website and social media postings to find out how you can join us in these activities and to learn how you can use the database in your research and educational activities.
- The Impact of Electronic Publishing on the Academic Community. From private data to public knowledge. Kennard, O. (1996) Portland Press.
- Allen, F. H., Bellard, S., Brice, M. D., Cartwright, B. A., Doubleday, A., Higgs, H., Hummelink, T., Hummelink-Peters, B. G., Kennard, O., Motherwell, W. D. S., Rodgers, J. R. & Watson, D. G. (1979). Acta Cryst. B35, 2331-2339.
![]()