Perspectives on structural databases in drug discovery at the first BAGIM/SAGIM joint event
CCDC was honored to sponsor and present at the first joint virtual meeting of the Southern California and Boston Area Groups for Informatics and Modeling (SAGIM and BAGIM) last Thursday, April 15th. Over 150 participants attended to discuss the value of information extracted from structural databases and the important metrics for database curation.
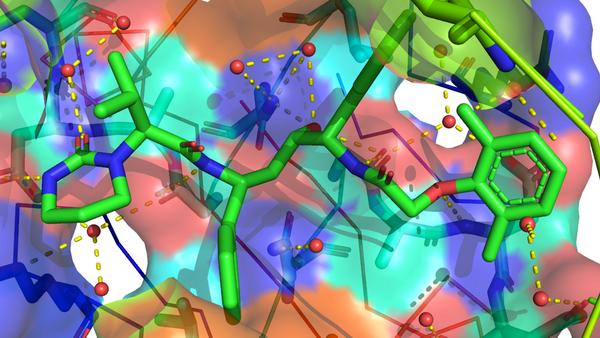
Doree Sitkoff – Principal Scientist in Computational Chemistry Discovery Chemistry, Janssen Research and Development – spoke first on the use of conformational analysis provided by Mogul to screen docked solutions. The method computes ligand geometry fitness score, which estimates the torsional health of a docked pose. This provides a supplement to the calculated docking score. Mogul is frequently used to estimate whether the input structure for docking has unusual bond lengths and angles, but post-processing docking results with a similar methodology on torsional angles is a fresh addition to the toolbox of a computational chemist.
Gregory Warren – Director of Computational Chemistry, DeepCure – discussed the appropriate metrics for X-ray and neutron diffraction crystal structures. The reliability of the crystal structure data is crucial throughout the process of drug discovery, and conclusions based on bad data may become costly to the entire project.
Vera Prytkova – Research and Applications Scientist, CCDC – In my talk, I focused on the information that can be extracted from structural databases, such as the Cambridge Structural Database (CSD) and the Protein Data Bank (PDB), in order to guide drug discovery research. The topics covered included pharmacophore-based searches of the databases, extracting information about molecular conformations and intermolecular interactions to assess the likelihood of conformation, and interaction of a newly designed drug and the use of structural data in solid form design.
Structural databases provide an ocean of knowledge, and we as a community are continuing to explore the metrics necessary to ensure the usefulness of such aggregate data as well as new ways to guide structural drug design. I deeply appreciate the effort our invited speakers have put into their presentations, and I am looking forward to seeing structural information continuing to play a key role in drug discovery research.
View my presentation, “Structural databases in drug discovery: Extracting useful information from the CSD and the PDB”
Learn more about SAGIM and BAGIM.
View the speakers’ full abstracts.